Introduction
There’s a bad bug in the Windows Embedded Compact scheduler code on WEC7 and WEC2013 (and possibly earlier versions as well) that causes the OS to become non-deterministic. This means WEC7 and WEC2013 can NOT be called a Real-Time Operating System as long as this bug is present.
We have reported this bug to Microsoft, together with the fix, but unfortunately Microsoft has responded with:
- “This would impact the kernel and the risks to taking this on far outweigh the good that would come of it so in the interest of not destabilizing the product we have opted to forgo fixing this issue at this time.”
The fix we provided has been thoroughly tested by us and has shown the kernel works absolutely fine with it in place. The fix is inside PRIVATE code so it is really Microsoft who would need to update this code and provide updated binaries, if only to prevent a maintenance nightmare.
The bug
The CE kernel keeps a table containing all handles. Access to this kernel table is controlled by a locking mechanism. If a thread requests a handle the kernel would need to alter the handle table (to add the handle). In this case, the thread requesting a handle becomes a “writer” of the handle table.
If a thread is merely requesting an existing handle from the handle table without any need to alter the handle table, the thread requesting the existing handle becomes a “reader”.
“Writers” to the handle table acquire an exclusive lock whereas “readers” just increase the lock count.
If a “reader” tries to increase the lock count but the handle table is already owned and exclusively locked by a “writer”, the “reader” blocks until the “writer” releases the exclusive lock. In this case priority inversion should occur, so that the lower priority “writer” thread gets scheduled and will release the exclusive lock as soon as possible so that the higher priority “reader” thread can continue as soon as possible.
Due to a bug in the CE kernel handle table locking code, this priority inversion sometimes does not occur resulting in high priority threads to have to wait until many lower priority threads run their thread quantum.
This absolutely and completely breaks the real-time scheduling mechanism of Windows Embedded Compact.
The code acquiring the handle table lock requires two steps:
- Acquire the lock
- Set the owner of the lock
The problem is that the Microsoft kernel code does not make this an atomic operation, meaning that a low priority “writer” thread can be pre-empted by a high priority “reader” thread in between step 1 and 2. The resulting situation of that pre-emption is that the handle table is locked, but the scheduler has no record of which thread owns the lock, and thus cannot apply priority inversion. The higher priority “reader” thread now has to wait for the lower priority “writer” thread to be scheduled at its original low priority. If there are any other threads active in the system at equal or higher priority than the priority of the “writer” thread, it means the high priority “reader” thread will have to wait for all these lower priority threads to run before it is allowed to continue.
It is important to note that the handle table contains ALL handles and the lock is a table-wide lock, meaning that ANY handle access can cause this situation. One thread can be using a file system handle, while another thread uses a completely unrelated device driver handle. There is no need for both threads to try to access the same handle.
The bug commonly shows itself in real-world scenarios, but so far hasn’t been diagnosed properly. The reason is that the bug is caused by a locking mechanism completely hidden from the user and it is therefore extremely difficult to find the root cause of this bug. Application code will look completely correct and connecting the issue with another, apparently completely unrelated, active thread in the system that together are causing this issue to arise, is extremely difficult.
The proof
We have created example code that quickly and reliably shows that this bug occurs on all systems running the WEC7 or WEC2013 OS. We have not tried CE6 yet, but it is very likely this bug exists in that version of the OS as well, and likely also in earlier versions of the OS.
The example code consists of a very simple stream interface device driver and a test application that creates:
-
- One low priority “writer” thread that gets, uses and releases a handle to the 1st instance of the device driver in a tight loop without yielding (so no sleep). This thread runs at priority 255 (idle).
- One low priority “busy” thread per core, simply executing a tight loop for 100 ms without yielding (so no sleep and no use of any handle). These threads run at priority 255 (so the “writer” thread gets scheduled in round-robin fashion together with these “busy” threads).
- One high priority “reader” thread that uses a handle to the 2nd instance of the device driver in a loop, sleeping for 1 ms before using the thread handle again. This thread runs at priority 0 (hard real-time).
The “reader” and “writer” threads call a function inside the device driver instance that stalls (runs a tight loop without yielding) for 100 us.
The busy threads are there to make sure all cores are busy all the time and the low priority “writer” thread gets scheduled in round-robin fashion together with these busy threads.
The high priority “reader” thread will pre-empt all of these low priority threads every 1 ms.
The high priority thread tracks how long the DeviceIoControl call to the device driver takes, and breaks out if it detects the bug situation. Below is the output of the test run on a Nitrogen6X iMX6 Quad with only a single core active. We only activated a single core to show that many other threads can be scheduled in succession before our high priority thread can be scheduled again. This is explained in more detail later. It is important to note that the bug also occurs when enabling all 4 cores (and we have a busy thread on each core).
\> rttapp
Handle table lock mechanism bug test started at 12:06:10 on 2018/08/15
Low priority writer thread 1 started on processor 1
Low priority busy thread 1 started on processor 1
High priority reader thread 0 stall of 100 us took maximum 120 us.
Low priority busy thread 2 started on processor 1
High priority reader thread 0 stall of 100 us took maximum 149 us.
Low priority busy thread 3 started on processor 1
High priority reader thread 0 stall of 100 us took maximum 241 us.
Low priority busy thread 4 started on processor 1
High priority reader thread 0 stall of 100 us took maximum 242 us.
High priority reader thread 0 stall of 100 us took maximum 252 us.
High priority reader thread 0 stall of 100 us took maximum 253 us.
High priority reader thread 0 stall of 100 us took maximum 254 us.
High priority reader thread 0 stall of 100 us took maximum 306 us.
High priority reader thread 0 stall of 100 us took maximum 399156 us.
Could not copy OSCapture.clg to \Release, error 3
ERROR: High priority reader thread 0 stall of 100 us took 399156 us!
Handle table lock mechanism bug test ended at 12:07:18 on 2018/08/15
\>
It’s only a matter of time before the high priority “reader” thread pre-empts the low priority “writer” thread in between it acquiring the lock and setting itself as the owner of the lock. As you can see in the above example it took a little over a minute to show the bug, and the result is that our priority 0 real-time thread had to wait almost 400 ms before being scheduled again!
If the test application code detects the bug, it calls “OSCapture” with parameter “-c” so that OSCapture writes the CELog RAM buffer to a file in the root called “OSCapture.clg”. It will then try to copy this file to the \Release folder, which is only available in a KITL enabled kernel. We ran the above test on a Shipbuild kernel (so without KITL enabled), hence the copy to \Release failed. We used FTP to copy the OSCapture.clg file to our Shipbuild’s _FLATRELEASEDIR and opened the file from there with Kernel Tracker:
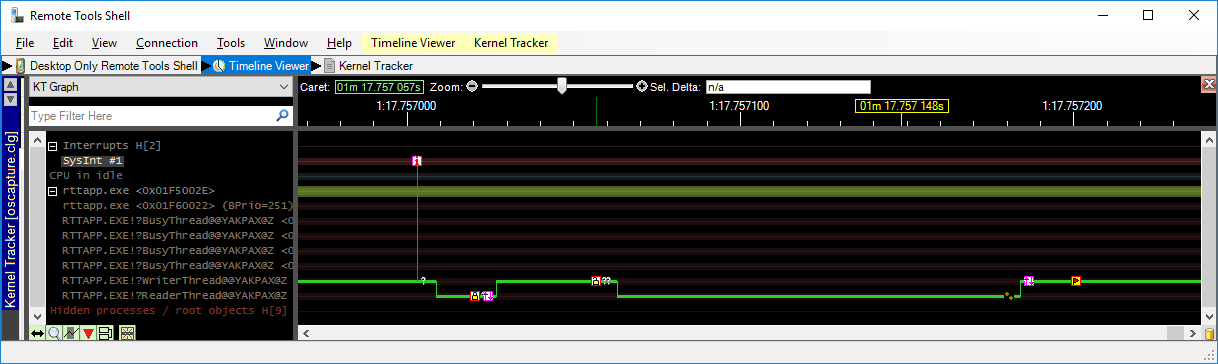
The above Kernel Tracker screenshot shows a “good” situation. As you can see, the low priority “writer” thread is running when it gets pre-empted by our high priority “reader” thread. In the good situation, the high priority “reader” thread tries to get the handle table lock, but the table is locked by the low priority “writer” thread and the owner thread is properly set. The kernel now inverts the priorities of the high priority “reader” thread and the low priority “writer” thread. Now the low priority “writer” thread runs at priority 0 and thus gets scheduled immediately so it can finish its work asap and release the handle table lock. As soon as it has released the handle table lock, the priorities are inverted again and our high priority “reader” gets the handle table lock and gets scheduled immediately. It now continues execution; real-time deterministic behaviour is guaranteed.
Theoretical total time it would take for the high priority “reader” thread to finish is:
(Execution time of high priority thread) + (Remaining execution time of low priority thread) + some overhead.
In a “bad” situation, the high priority “reader” thread preempts the low priority “writer” thread in between it getting the handle lock and setting itself as the owner of the lock:
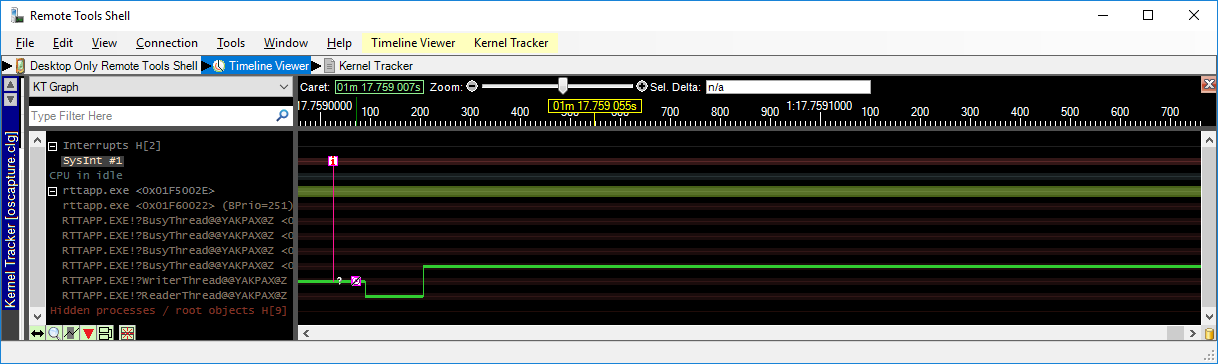
The above Kernel Tracker screenshot shows a “bad” situation. As you can see, the low priority “writer” thread is running when it gets pre-empted by our high priority “reader” thread. In the bad situation, the pre-emption of the low priority “writer” thread happens in between it locking the table (step 1) and setting itself as the lock owner (step 2). Now the high priority “reader” thread wants to lock the handle table, but the table is locked by the low priority “writer” thread without the owner thread properly set. The kernel now has no idea which thread owns the lock and thus cannot invert priorities. The scheduler now simply schedules the next thread that is ready to run. This thread runs for an entire thread quantum as well as any other thread ready to run after that. In our case there are 4 busy threads that all run an entire thread quantum before our low priority “writer” thread gets scheduled again:
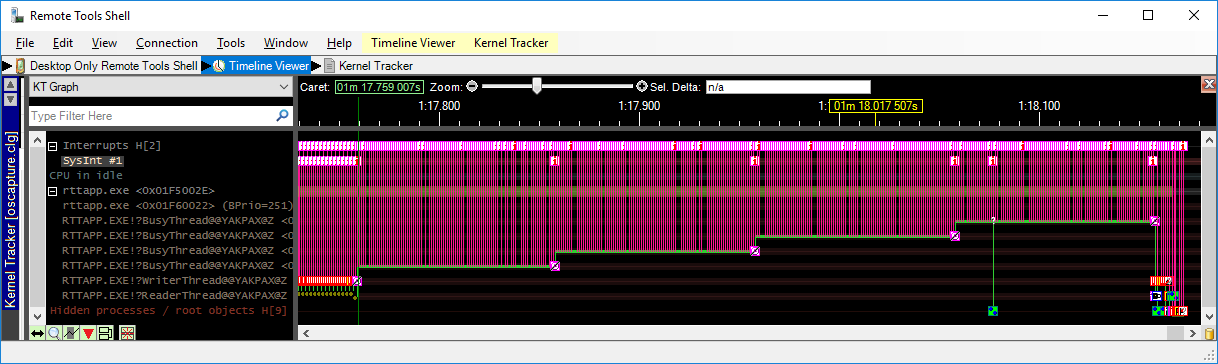

As soon as the low priority “writer” thread gets scheduled again, it resumes at step 2 and sets itself as owner of the handle table lock so now the scheduler knows which thread to invert the priority of. Immediately the low priority “writer” thread gets scheduled again so it can finish its work asap and release the lock. When that happens, the priorities are inverted again and our high priority “reader” thread can finally run, but only after having had to wait for all these other low priority threads to have run through their thread quantum.
As you can see; deterministic behaviour is completely broken and thus we cannot say Windows Embedded Compact is a real-time operating system with this bug in place.
Luckily, the kernel code containing the bug is available when you install the shared source. It is possible to clone, modify and build this kernel code so that locking the table and setting the owner becomes an atomic operation. With this fix in place, real-time deterministic behaviour is restored and Windows Embedded Compact can be labelled as an RTOS again.
Note: the GuruCE iMX6 BSP will include this fix in our upcoming release. Current customers can request this fix right away.
We are still hopeful Microsoft will change its opinion and release an update for WEC7 and WEC2013 to fix this issue. If that happens, we will update this article to reflect that.
The example code showing the kernel handle table locking bug and a pdf version of this article are available here.
UPDATE: Microsoft fixed this bug in WEC2013 (but unfortunately not in WEC7), see this blogpost.

 We just received a report from one of our customers that saw their high priority thread on WEC2013 not being scheduled for a long time, even though that thread was set to the highest priority in the entire system.
We just received a report from one of our customers that saw their high priority thread on WEC2013 not being scheduled for a long time, even though that thread was set to the highest priority in the entire system.